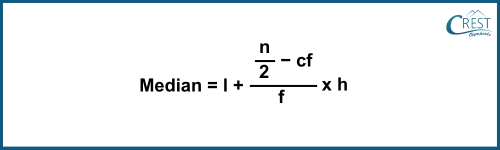
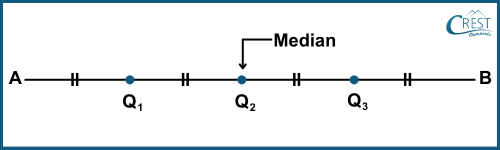
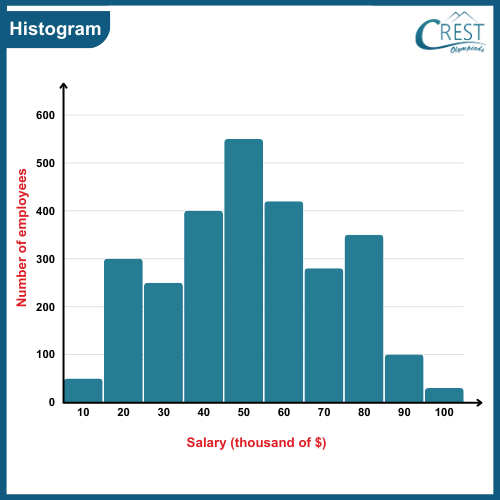
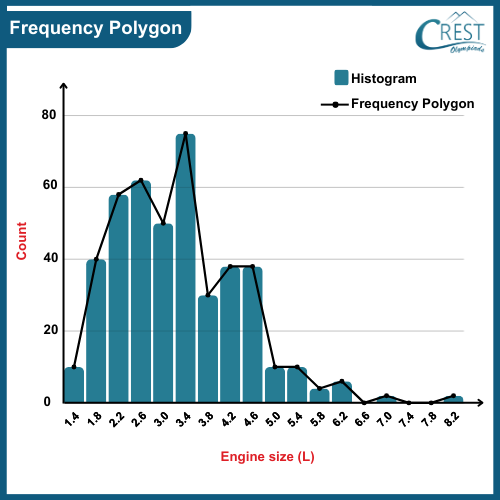
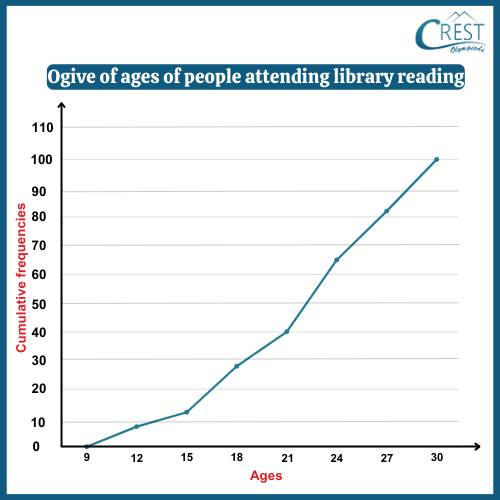
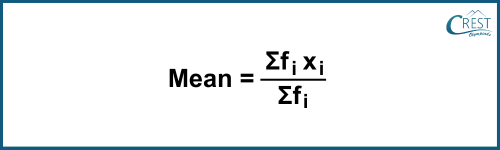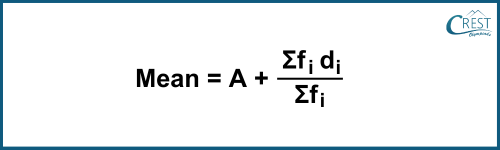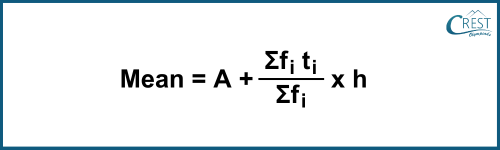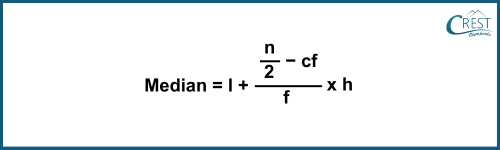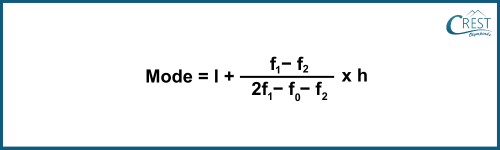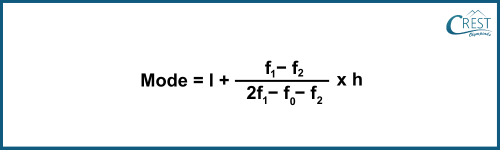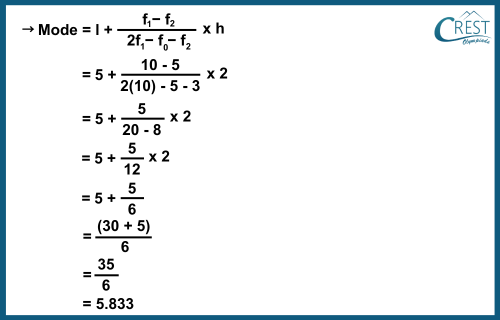-
Olympiads
- CREST Mathematics Olympiad (CMO)
- CREST English Olympiad (CEO)
- CREST Science Olympiad (CSO)
- CREST Cyber Olympiad (CCO)
- CREST Reasoning Olympiad (CRO)
- CREST International Drawing Olympiad (CIDO)
- International Green Warrior Olympiad (IGWO)
- CREST Mental Maths Olympiad (CMMO)
- CREST International Spell Bee - Summer (CSB)
- CREST International Spell Bee - Winter (CSBW)
- International Teacher Olympiads
- Class wise
- FAQs
- Student Connect
- Preparation
- Free Trial
- School Registration
- Become a Coordinator
- Explore More
Olympiad Exam Registration Started for 2026-27 | Check 2026-27 Olympiad Exam Dates | Join our WhatsApp Channel for Exam Updates | Buy 2026-27 Olympiad books here | Download Free Maths Olympiad Printable Worksheets | Download Free Science Olympiad Printable Worksheets | Download Free English Olympiad Printable Worksheets |
Check Previous Years Papers